Reddit Product Sentiment Monitor (POC).
An automated pipeline that ingests niche community discussions, filters for product relevancy using LLMs, and structures the data for sentiment analysis.
Role
Product Engineer
Timeline
Current Project (POC)
Outcome
Successfully processing live data streams from 5+ subreddits with automated noise filtering and sentiment scoring.
Tech Stack
The Concept
Product discovery often relies on disjointed manual research—scrolling through Reddit threads, saving bookmarks, and trying to mentally aggregate “the vibe” of a community. I wanted to validate if this process could be automated: Can an AI agent effectively separate signal from noise in messy community data?
This project is a functional Proof of Concept (POC) designed to ingest, filter, and analyze commentary from specific subreddits (e.g., r/LegalTech, r/SaaS) to build a structured dataset of user sentiment over time.
Current Architecture (The Pipeline)
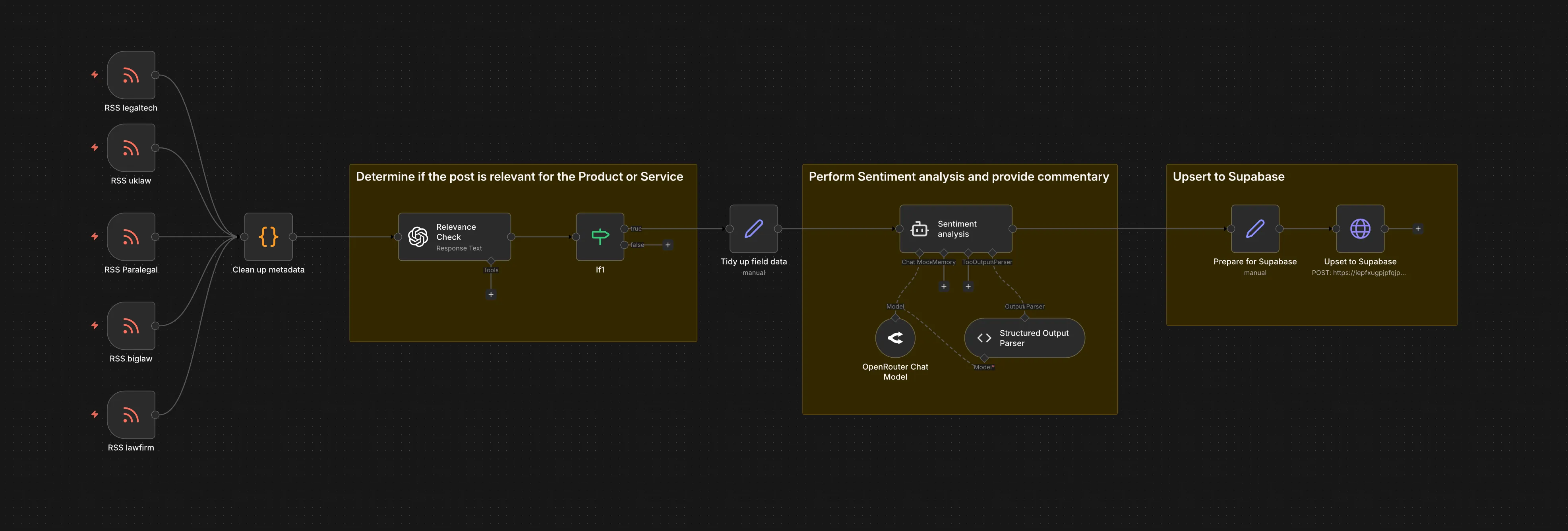
The core of this system is an n8n workflow that acts as the orchestrator. Unlike standard social listening tools that rely on simple keyword matching, this pipeline uses LLMs to understand context.
1. Ingestion Layer
- Source: The system monitors RSS feeds from targeted subreddits.
- Trigger: Polling occurs at regular intervals to capture new discussions as they happen.
2. Intelligence Layer (The “Brain”)
- Relevance Agent: Every incoming post is sent to an LLM (via OpenRouter) with a specific system prompt: “Is this post discussing a product, service, or pain point relevant to [Domain]?” This filters out ~60% of the noise (memes, meta-discussion, off-topic rants).
- Sentiment & Metadata: If relevant, a second agent analyses the text to:
- Score sentiment (-1.0 to +1.0).
- Extract key entities (Competitor names, specific features).
- Generate a one-sentence summary of the “User Voice.”
3. Storage & Visualisation
- Database: Structured JSON output is upserted into Supabase (PostgreSQL).
- Frontend: Currently, the data feeds into a simple Visualisation dashboard that tracks sentiment trends over time and lists high-relevance posts.
The Pivot: From “Dashboard” to “Active Intelligence”
While the current dashboard is useful for retrospective analysis, I have identified that the true value lies in interrogating the data rather than just looking at charts. I am currently refactoring the project to move beyond simple Visualisation.
Future Roadmap: The “Analyst Agent”
I am evolving this POC into a RAG (Retrieval-Augmented Generation) powered platform with two distinct outputs:
1. Contextual Chatbot (RAG Pipeline) Instead of filtering columns in a dashboard, I want to ask the data questions:
- “What are the top 3 complaints about [Competitor X] this month?”
- “Has sentiment shifted regarding [Feature Y] since the last update?” This requires vectorising the Supabase data and building a retrieval chain that allows an LLM to “read” the accumulated community history before answering.
2. Agentic Weekly Briefing Moving from “Pull” to “Push.” An autonomous agent will run every Monday morning, look at the previous 7 days of data, identify anomalies or clusters of discussion, and write a natural-language email report. This shifts the value proposition from “Here is a graph” to “Here is what you need to know.”
Key Learnings So Far
- Prompt Engineering vs. Noise: Reddit data is notoriously messy. I spent significant time tuning the “Relevance Check” prompt. “Generic” prompts let too much noise through; highly specific prompts missed valuable edge cases.
- Cost Management: Running two distinct LLM calls per Reddit post gets expensive quickly. I optimised this by using cheaper models (like GPT-4o-mini or Haiku) for the initial boolean “Relevance” check, saving the more capable models for the complex sentiment extraction.
- RSS Limitations: RSS feeds only provide a snapshot. For the V2 RAG pipeline, I am exploring the Reddit API directly to fetch full comment trees, as the real insights are often in the comments, not the post body.